What is Content Scraping?
Content scraping refers to the automated process of extracting data or information from websites.
This practice involves using bots, often called web scrapers or web crawlers, to retrieve content from web pages, such as text, images, videos, or entire page structures. The scraped data can then be used for purposes like market research, data analysis, competitive analysis, or populating databases.
What is Content Scraping Used for?
Content scraping is typically used for extracting data from websites for various purposes, such as market research, where businesses analyze competitors’ products and pricing; data analysis, to gather large datasets for research or analytics; competitive analysis, to monitor industry trends and strategies; and populating databases, by collecting and aggregating information from multiple sources into a centralized system.
How Do Bots Scrape Content?
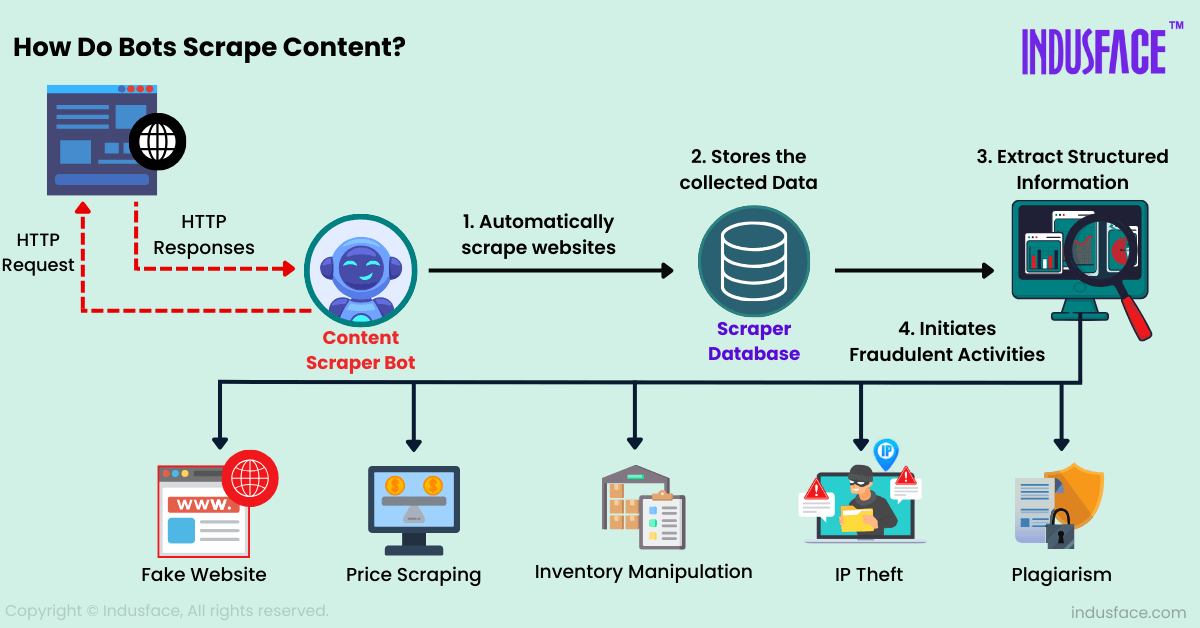
There are typically 5 steps in the process
- Send Requests: The bot sends an HTTP request to the target website’s server, typically using GET requests to access the webpage’s HTML content.
- Fetch HTML Content: The server responds with the HTML code of the requested webpage. The bot receives this HTML content for further processing.
- Parse HTML: The bot parses the HTML code to understand the structure of the webpage. This involves identifying tags, attributes, and the hierarchical structure of elements on the page. Libraries such as Beautiful Soup (Python) or Cheerio (JavaScript) are commonly used for this purpose.
- Navigate the DOM and Extract the Data: The bot navigates the Document Object Model (DOM) of the webpage to locate specific elements that contain the desired data.
Typically, bots use CSS selectors, XPath and JavaScript execution to traverse the DOM and extract data.
CSS Selectors
Here’s an example of using CSS selectors with Beautiful Soup in Python to scrape product name and product price from an e-commerce page:
from bs4 import BeautifulSoup
html = '<div class="product"><h2 class="name">Product Name</h2><p class="price">$19.99</p></div>'
soup = BeautifulSoup(html, 'html.parser')
product_name = soup.select_one('.product .name').text
product_price = soup.select_one('.product .price').text
print(product_name) # Output: Product Name
print(product_price) # Output: $19.99
In this example, .product .name selects the <h2> element with the class “name” inside the <div> with the class “product”, and .product .price selects the <p> element with the class “price” within the same <div>.
XPath
The other option is using XPath expressions to locate elements based on their paths in the DOM tree.
Here’s an example of using XPath with Beautiful Soup in Python to scrape product name and product price from an e-commerce page:
from lxml import html
html_content = '''
<div class="product">
<h2 class="name">Product Name</h2>
<p class="price">$19.99</p>
</div>
'''
tree = html.fromstring(html_content)
product_name = tree.xpath('//div[@class="product"]/h2[@class="name"]/text()')[0]
product_price = tree.xpath('//div[@class="product"]/p[@class="price"]/text()')[0]
print(product_name) # Output: Product Name
print(product_price) # Output: $19.99
In this example, //div[@class=”product”]/h2[@class=”name”]/text() selects the text content of the <h2> element with the class “name” inside the <div> with the class “product”, and //div[@class=”product”]/p[@class=”price”]/text() selects the text content of the <p> element with the class “price” within the same <div>.
JavaScript Execution
The final option is to render the complete webpage before extracting data. Tools like Puppeteer or Selenium facilitate this process.
Here’s an example of using Puppeteer, a Node.js library, to scrape content from an e-commerce site that requires JavaScript execution to load the data:
const puppeteer = require('puppeteer');
(async () => {
// Launch a headless browser
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Navigate to the webpage
await page.goto('https://example.com');
// Wait for the content to load (e.g., an element with class "product")
await page.waitForSelector('.product');
// Extract data
const productData = await page.evaluate(() => {
const productName = document.querySelector('.product .name').innerText;
const productPrice = document.querySelector('.product .price').innerText;
return { name: productName, price: productPrice };
});
console.log(productData); // Output: { name: 'Product Name', price: '$19.99' }
// Close the browser
await browser.close();
})();
In this example, Puppeteer is used to control a headless browser that navigates to a webpage and waits for an element with the class “product” to load. Once the element is loaded, it extracts the text content of the elements with the classes “name” and “price” inside the “product” element. This approach ensures that content loaded dynamically by JavaScript is captured.
While the above examples, extract just text, these can be used to extract links, images and other types of content.
Once the data is extracted, it is stored in a structured format, such as JSON, CSV, or a database, for further analysis and use.
What Kinds of Content Do Scraping Bots Target?
Scraping bots target a wide range of content on the web, depending on the specific needs and objectives of the user.
Here are some common types of content that scraping bots typically target:
| Content Type | Targeted Content Example | Affected Industries |
| Text Content | Articles, Blog Posts | Media, Journalism, Content Marketing |
| Product Descriptions | E-commerce, Retail | |
| Reviews, Comments | E-commerce, Social Media | |
| Forum Posts | Community Boards, Online Forums | |
| Structured Data | Tables, Lists | Finance, Research, Data Analysis |
| Forms | Market Research, Data Collection | |
| Multimedia Content | Images | E-commerce, Social Media, Marketing |
| Videos | Media, Entertainment, Education | |
| Audio Files | Music, Podcasts, Entertainment | |
| Metadata | Page Titles, Meta Descriptions | SEO, Digital Marketing |
| Headings | SEO, Content Structuring | |
| Attributes | Web Development, SEO | |
| Links | Internal Links | Web Development, SEO |
| External Links | SEO, Digital Marketing | |
| Broken Links | Web Development, SEO | |
| Price Information | Product Prices | E-commerce, Retail |
| Comparative Prices | E-commerce, Market Research | |
| Contact Information | Email Addresses | Marketing, Sales |
| Phone Numbers | Marketing, Sales | |
| Social Media Handles | Marketing, Social Media | |
| Geographical Data | Addresses | Real Estate, Logistics |
| Coordinates | Travel, Mapping Services | |
| Financial Data | Stock Prices | Finance, Investment |
| Cryptocurrency Data | Finance, Cryptocurrency | |
| Market Data | Finance, Economics | |
| Job Listings | Job Postings | Recruitment, Job Boards |
| Company Profiles | Recruitment, Market Research |
Why is Scraping Harmful?
Scraping can be harmful as it could be used to optimize competitor listings, undercut prices and manipulate inventory on e-commerce platforms. For other industries, this could mean infringing on Intellectual Property and violating terms of service of using the product.
For example, in 2019, Amazon took legal action against firms like ZonTools for scraping its product data. This scraping not only infringed on Amazon’s intellectual property rights but also disrupted its operations and competitive advantage by extracting and misusing vast amounts of data.
Such activities can compromise user privacy, lead to data misuse, and cause significant operational challenges, highlighting the potential negative impact of scraping on businesses and consumers alike.
Under bot attack? Get emergency help.
How to Prevent Scraping?
Preventing scraping involves implementing a combination of technical and legal measures to protect web content. Techniques include using CAPTCHA systems to verify human users, employing rate limiting and IP blocking to detect and prevent excessive requests, and utilizing web application firewalls (WAFs) to filter out malicious traffic.
Additionally, websites can obscure or change the structure of their HTML to make scraping more difficult. Legal measures, such as updating the terms of service to explicitly prohibit scraping and pursuing legal action against violators, also serve as deterrents. Together, these strategies help safeguard website data and maintain the integrity of web services.
What Techniques Does AppTrana WAAP Use to Block Scraping Bots?
AppTrana WAAP bot management module uses multi-layered mitigation methods to block scraping bots.
At the most basic level, IP reputation, bad user agents, Tor IPs and other filters are used to block bots right away.
Then the more advanced features leverage machine learning for behavioural analysis and anomaly scoring. For example, if an average user browses 3-4 products per session but in the current session, the user agent is browsing 20+ products and spending abnormally low amount of time on each page, then the anomaly score is updated, and the bot gets blocked once a certain threshold is reached.
Even on mitigation methods, the ML model uses a layered approach where it starts with tarpitting and then progressively goes to CAPTCHA or drops requests right away.